

While Meta deals with artificial intelligence in the form of its constantly-changing content tagging system, the company’s research wing is hard at work on novel generative AI technology, including a new Meta 3D Gen platform that delivers text-to-3D asset generation with high-quality geometry and texture.
“This system can generate 3D assets with high-resolution textures & material maps end-to-end with results that are superior in quality to previous state-of-the-art solutions — at 3-10x the speed of previous work,” Meta AI explains on Threads.
Post by @aiatmeta
View on Threads
Meta 3D Gen (3DGen) can create 3D assets and textures from a simple text prompt in under a minute, per Meta’s research paper. This is functionally similar to text-to-image generators like Midjourney and Adobe Firefly, but 3DGen builds fully 3D models with underlying mesh structures that support physically-based rendering (PBR). This means that the 3D models generated by Meta 3DGen can be used in real-world modeling and rendering applications.

“Meta 3D Gen is a two-stage method that combines two components, one for text-to-3D generation and one for text-to-texture generation, respectively,” Meta explains, adding that this approach results in “higher-quality 3D generation for immersive content creation.”
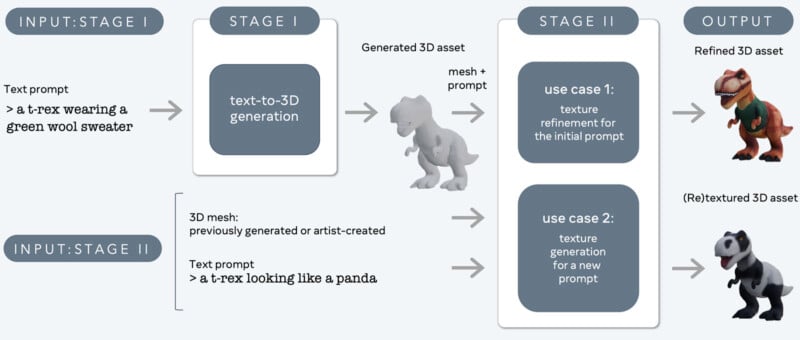
3DGen combines two of Meta’s foundational generative models, AssetGen and TextureGen, focusing on the relative strengths of each. Meta says that based on feedback from professional 3D artists, its new 3DGen technology is preferred over competing text-to-3D models “a majority of the time” while being three to 60 times faster.

It is worth noting that by separating mesh models and texture maps, 3DGen promises significant control over the final output and allows for the iterative refinement common to text-to-image generators. Users can adjust the input for texture style without tweaking the underlying model.

Meta’s complete technical paper about 3DGen goes into significantly more detail and shows evaluative testing results compared to other text-to-3D models.
Image credits: Meta AI
Source link




